NetActuate has launched Global Edge Storage
Explore

NetActuate has launched Global Edge Storage

By clicking "Accept all" you allow cookies that improve your experience on our site, help us analyze site performance and usage, and enable us to show relevant marketing content. You can manage cookie settings below. By clicking “Confirm selection” you agree with the current settings.


By Mark Mahle, Founder & CEO, NetActuate
On November 18, 2025, A massive Cloudflare outage, the company’s most extensive since 2019, caused a significant portion of the internet to go dark. Users around the world experienced several hours of downtime as apps and services—from ChatGPT to Spotify, YouTube, Uber, and X—became unreachable.
Cloudflare responded quickly with a detailed and transparent blog post outlining exactly what went wrong, what was affected, and how they plan to prevent it from happening again. Their full incident report is available here: Cloudflare outage on November 18, 2025.
The issue this time wasn’t the result of a cyberattack or external interference. Instead, it was triggered by an internal configuration change: specifically, an update to one of Cloudflare’s database system permissions. This change unintentionally caused the database to output duplicate entries into a “feature file” used by Cloudflare’s Bot Management system.
That system, which employs machine learning to detect and manage bot traffic across their global infrastructure, is typically a strength. However, in this case, the change led to an unexpected increase in duplicate “feature” rows. This overwhelmed the system and caused widespread instability, affecting Cloudflare’s core services and the many platforms that rely on them.
In a world where milliseconds matter and downtime equates to lost revenue and user trust, even a seemingly small configuration oversight can cascade quickly across globally distributed infrastructure. Cloudflare’s quick action and transparency in sharing root cause analysis, impact, and mitigation steps is commendable, and a good reminder of how critical resilience engineering is in today’s internet.
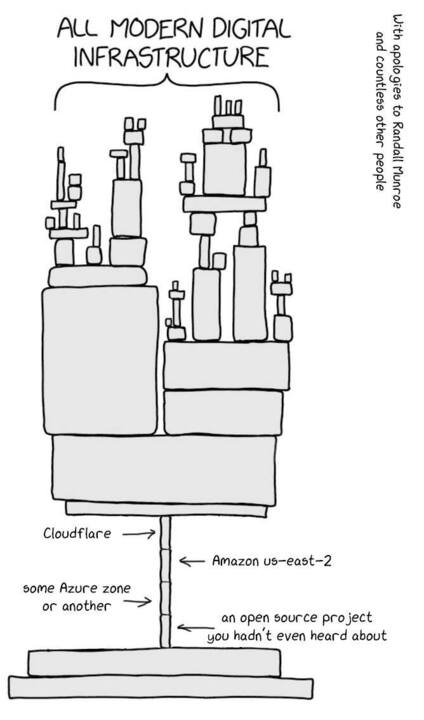
Cloudflare’s transparency and thorough analysis deserve credit. Incidents like these serve as powerful reminders: even with extensive automation and best practices, managing a resilient, global infrastructure remains inherently complex. Subtle, well-intentioned changes can have outsized consequences when deployed at scale.
At the heart of this lesson is a broader truth: resilience comes from ownership, visibility, and control. The more you depend on external systems—especially for core functions like DNS—the more vulnerable you are to someone else’s mistakes.
At NetActuate, we believe that owning key pieces of your infrastructure puts you in the driver’s seat. That includes controlling your own DNS, rather than fully delegating to third-party providers. DNS is often the first and most critical failure point during outages. It’s also one of the easiest places to build resilience if you control it.
Our global platform was purpose-built for this kind of resiliency. With 45+ edge locations, Anycast routing, automated failover, and decades of operational experience, we help our customers maintain uptime and performance even when major upstream providers go down.
But infrastructure alone isn’t enough. We collaborate closely with customers to design solutions that match their application architecture, user base, and performance goals—without sacrificing reliability.
If your application or users were affected by the recent Cloudflare outage—or if you’re simply looking to strengthen your infrastructure before the next outage”—we invite you to take the next step:
Downtime is never convenient—but every incident offers a chance to learn, improve, and adapt. Let’s build a more resilient internet together.
Reach out to learn how our global platform can power your next deployment. Fast, secure, and built for scale.
.svg)

















